OpenAI Introduces Sparse Circuits for Interpretable AI
OpenAI unveils sparse circuits, enhancing AI transparency and safety by identifying minimal subnetworks within neural networks.
OpenAI Introduces Sparse Circuits for Interpretable AI
OpenAI has announced a major advancement in the field of mechanistic interpretability with its new approach to understanding neural networks through sparse circuits. This development, revealed in November 2025, promises to make large-scale AI models more transparent, easier to debug, and safer to deploy—addressing long-standing concerns about the “black box” nature of deep learning systems.
What Are Sparse Circuits?
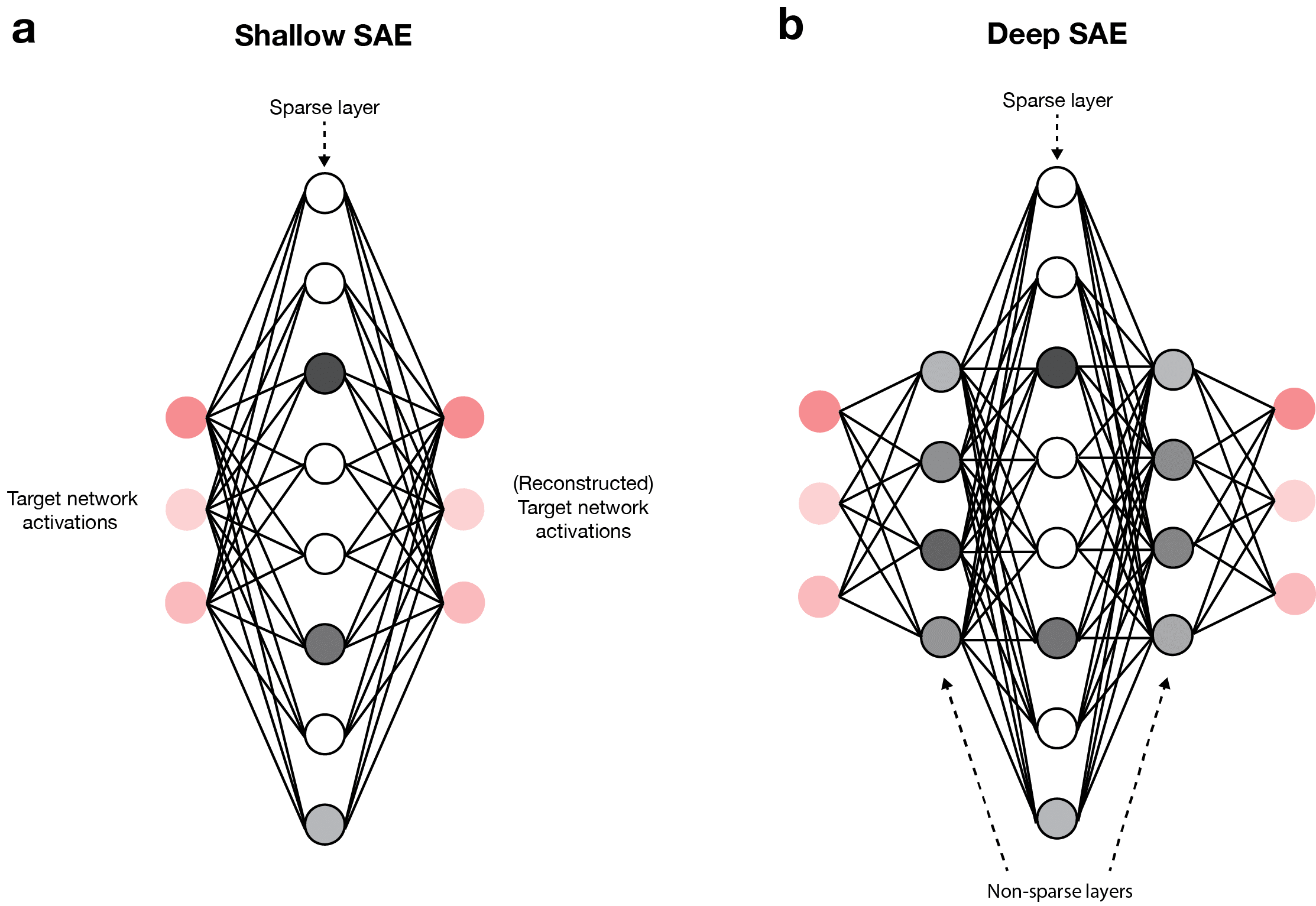
Sparse circuits refer to the identification and analysis of minimal subnetworks within large neural networks that are responsible for specific computations. Rather than treating the entire model as a monolithic entity, researchers isolate these sparse circuits—small clusters of neurons and connections that perform essential functions. This approach is rooted in the Lottery Ticket Hypothesis, which suggests that dense networks contain smaller, highly effective subnetworks that can be trained independently.
OpenAI’s latest work extends this concept to transformer-based models, such as GPT-4 and its successors, which have billions of parameters and are notoriously difficult to interpret. By applying techniques like activation sparsity and weight pruning, OpenAI can now pinpoint which neurons activate for specific tasks, making it possible to visualize and manipulate these circuits directly.
Key Features and Technical Advances
- Sparse Autoencoders (SAEs): OpenAI integrates SAEs to decompose model activations into interpretable features. Recent research, including a 2024 paper from Anthropic, has shown that SAEs can achieve up to 90% sparsity without sacrificing model performance.
- Cross-Layer Interaction Sparsity: New methods like Jacobian SAEs (JSAEs) and crosscoders help minimize unnecessary cross-layer connections, leading to simpler, more interpretable circuits. This is crucial for understanding how information flows through multi-layered models.
- Visualization Tools: OpenAI has developed tools that allow researchers and developers to visualize these sparse circuits, making it easier to trace decision-making processes and identify potential issues.
Industry Impact and Implications
The ability to understand and manipulate sparse circuits has far-reaching implications for the AI industry:
- Safety and Reliability: By making AI models more transparent, sparse circuits can accelerate debugging and safety checks, reducing the risk of unintended behaviors.
- Regulatory Compliance: As governments and organizations demand greater accountability from AI systems, sparse circuits provide a pathway to meet these requirements.
- Research and Development: Researchers can now explore the inner workings of AI models in unprecedented detail, potentially leading to new discoveries and innovations.
Visual Representations
Visualization of a sparse circuit within a transformer model, highlighting key neurons and connections. Diagram illustrating how Sparse Autoencoders decompose model activations into interpretable features. Visualization of a sparse circuit within a transformer model, highlighting key neurons and connections.
Visualization of a sparse circuit within a transformer model, highlighting key neurons and connections.
 Diagram illustrating how Sparse Autoencoders decompose model activations into interpretable features.
Diagram illustrating how Sparse Autoencoders decompose model activations into interpretable features.
Context and Future Directions
OpenAI’s work on sparse circuits builds on a growing body of research in mechanistic interpretability. As AI models continue to scale in size and complexity, the need for transparent and interpretable systems becomes increasingly urgent. Sparse circuits represent a significant step forward in this direction, offering a practical solution to one of the most pressing challenges in modern AI.
Looking ahead, OpenAI plans to expand its toolkit for sparse circuit analysis and make these tools available to the broader research community. This move could democratize access to advanced interpretability techniques, fostering collaboration and innovation across the field.
Conclusion
OpenAI’s breakthrough in sparse circuits marks a pivotal moment in the quest for interpretable AI. By making neural networks more transparent and easier to understand, this approach paves the way for safer, more reliable, and more accountable AI systems. As the technology continues to evolve, sparse circuits are likely to play a central role in shaping the future of artificial intelligence.



