xAI Releases Grok 4.1, Claiming Top Position on LMArena Leaderboard
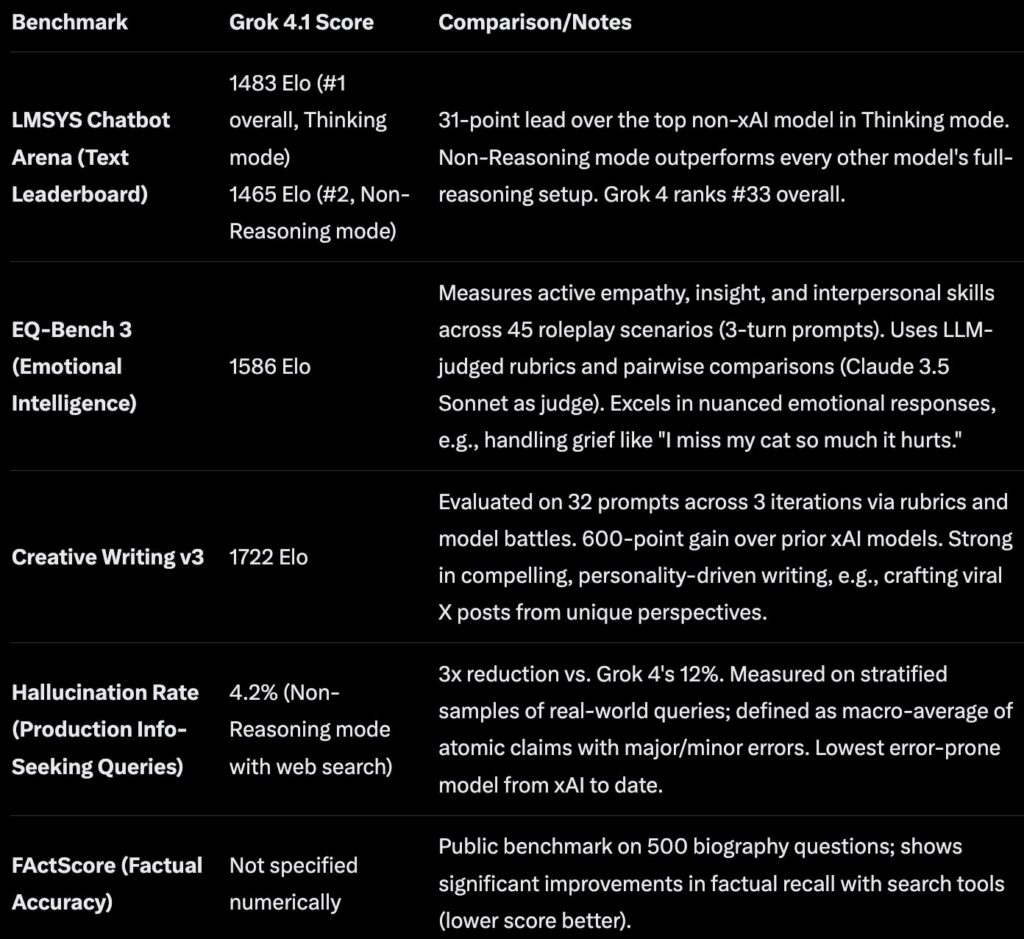
xAI has launched Grok 4.1, the latest iteration of its large language model. The company reports the model has achieved the top ranking on the LMArena leaderboard, marking a significant milestone in competitive AI performance benchmarking.
xAI Releases Grok 4.1, Claiming Top Position on LMArena Leaderboard
xAI has announced the release of Grok 4.1, the newest version of its large language model. According to the company's claims, the model has achieved the top ranking on the LMArena leaderboard, a widely-referenced benchmark for evaluating large language model performance across diverse tasks and use cases.
Performance Claims and Leaderboard Standing
The LMArena leaderboard represents one of the most closely watched performance metrics in the AI industry. Models are ranked based on community voting and comparative evaluations across a range of prompts and tasks. xAI's announcement positions Grok 4.1 as the leading model on this particular benchmark, a distinction that carries significant weight in competitive AI development.
The leaderboard system operates through crowdsourced evaluation, where users compare model outputs side-by-side and vote on which response better addresses their query. This methodology aims to capture real-world utility rather than relying solely on synthetic benchmarks.
Technical Context and Market Implications
The release of Grok 4.1 comes amid intensifying competition in the large language model space. Major technology companies and AI research organizations continue to advance their models with incremental and substantial improvements. Performance on public leaderboards has become a key metric for demonstrating capability advancement and market positioning.
Key considerations around this release include:
- Benchmark specificity: Leaderboard rankings reflect performance on particular evaluation methodologies and may not universally translate to all real-world applications
- Iterative development: Version numbering (4.1) suggests incremental improvements over the previous Grok 4 release
- Competitive landscape: The AI model market remains highly competitive, with multiple organizations pursuing leadership positions across various performance metrics
Broader Context
The announcement reflects xAI's ongoing efforts to establish Grok as a competitive offering in the large language model market. Founded by Elon Musk, xAI has positioned itself as an alternative to established AI providers, emphasizing different approaches to model development and deployment.
Leaderboard performance serves as both a technical validation and a marketing tool in the AI industry. However, practitioners and researchers often note that benchmark rankings don't always correlate directly with performance on specific downstream tasks or user satisfaction in production environments.
Key Sources
- xAI official announcements regarding Grok 4.1 release and performance claims
- LMArena leaderboard methodology and rankings documentation
- Industry analysis of large language model competitive positioning
The release of Grok 4.1 represents another data point in the ongoing evolution of large language model capabilities. Whether this leaderboard achievement translates to broader market adoption and real-world utility will depend on factors including model reliability, cost efficiency, and performance on specific use cases that matter to end users and enterprises.



