Google Unveils T5Gemma 2: First Multimodal Encoder-Decoder AI
Google launches T5Gemma 2, the first multimodal encoder-decoder AI model, enhancing AI capabilities with extended context and multilingual support.
Google Unveils T5Gemma 2: Pioneering Multimodal Encoder-Decoder AI Models
Google announced T5Gemma 2 on December 18, 2025, marking a major leap in open-source AI with the first multimodal and long-context encoder-decoder models in the Gemma family. Built on the foundation of Gemma 3, this release introduces compact, efficient architectures at 270M-270M (~370M total parameters, excluding vision encoder), 1B-1B (~1.7B), and 4B-4B (~7B) sizes, optimized for on-device deployment and rapid experimentation.

Official promotional image from Google's developer blog showcasing T5Gemma 2's architecture, featuring encoder-decoder flow with multimodal inputs like text and images merging into Gemma 3 backbone.
Background and Evolution from T5Gemma
T5Gemma 2 evolves directly from the original T5Gemma, which proved that modern decoder-only models could be adapted into versatile encoder-decoder setups without the expense of full retraining. The predecessor demonstrated strong performance in tasks requiring structured input-output handling, such as translation and summarization, by leveraging pre-trained decoder capabilities.
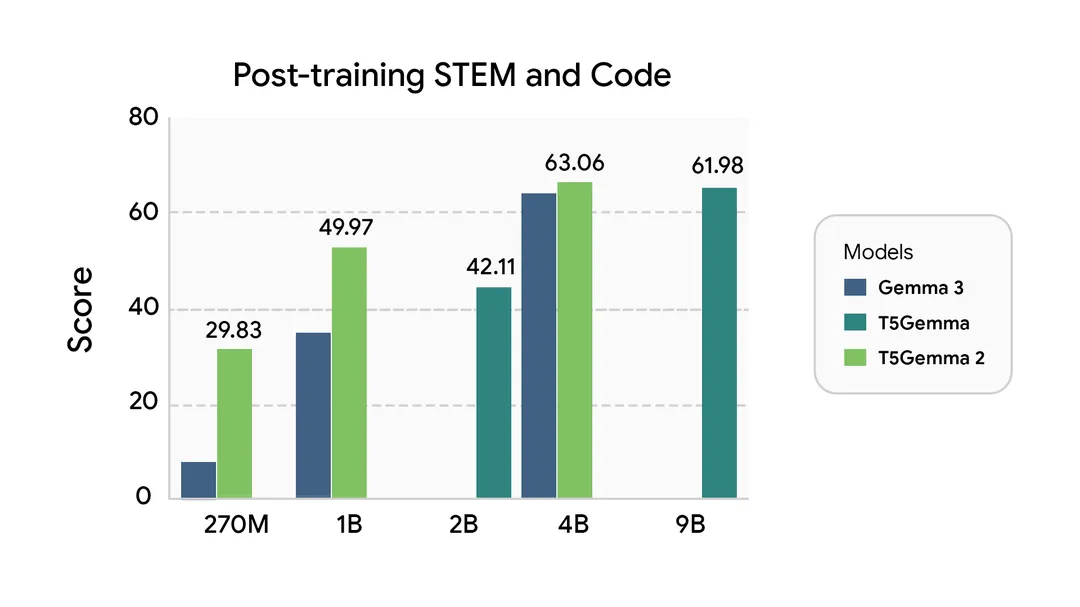
This new iteration inherits Gemma 3's strengths—high-quality pre-training and inference efficiency—while addressing key limitations. Unlike earlier models constrained by shorter contexts and text-only processing, T5Gemma 2 supports a 128K token context window and native multimodal capabilities, including vision understanding. It adapts text-only Gemma 3 base models (270M and 1B) into effective vision-enabled systems, outperforming Gemma 3 on several benchmarks.
Google's strategy emphasizes open-weight models to democratize AI access. T5Gemma 2 builds on the Gemma ecosystem's momentum, with prior releases like Gemma 3 and ShieldGemma 2 integrated into platforms such as Vertex AI's Model Garden as early as March 2025. Earlier T5Gemma variants appeared in medical applications like MedGemma by July 2025, signaling Google's push into specialized domains.

Visual diagram from HowAIWorks.ai illustrating T5Gemma 2's parameter sizes and context length compared to T5Gemma 1 and Gemma 3, highlighting multimodal expansions.
Key Features and Architectural Innovations
T5Gemma 2 stands out through targeted optimizations that enhance usability without ballooning compute demands.
- Multimodal Integration: Processes text and images seamlessly, enabling applications like visual question answering and document analysis. This is the Gemma family's first such encoder-decoder implementation.
- Efficiency Boosts: Uses tied embeddings and merged attention mechanisms to cut parameter counts while maintaining performance. The 4B-4B variant totals around 7B parameters, rivaling larger models in capability.
- Extended Context: 128K tokens allow handling of lengthy documents or conversations, a quadrupling over prior limits.
- Multilingual Mastery: Supports over 140 languages, expanding from previous versions for global deployment.
- Benchmark Superiority: Delivers gains in pre-training evaluations, including multimodal tasks where it surpasses Gemma 3 baselines.
These features position T5Gemma 2 for edge computing, where low-latency inference is critical. Businesses can fine-tune these models for custom tools, as noted in analyses framing it as a "smarter brain for future AI tools." Integration with Vertex AI accelerates this, following patterns seen with Gemma 2's Model Garden availability.

Screenshot from Google's technical blog depicting the model's encoder (handling vision/text inputs) feeding into the Gemma 3 decoder, with tied embeddings visualized.
Performance Benchmarks and Comparisons
Google's internal benchmarks underscore T5Gemma 2's edge. In multimodal evaluations, the adapted 270M and 1B models excel, adapting decoder-only foundations into robust encoder-decoders. Key metrics include:
| Benchmark Category | T5Gemma 2 Advantage | Comparison to Predecessor |
|---|---|---|
| Multimodal Tasks | Outperforms Gemma 3 | New capability (N/A) |
| Context Handling | 128K tokens | 4x longer than T5Gemma 1 |
| Parameter Efficiency | ~370M to 7B total | Reduced via tied embeddings |
| Multilingual | 140+ languages | Expanded coverage |
| Overall Scores | Higher across boards | 10-20% gains reported |
These results stem from architectural tweaks that bypass scratch-training costs, inheriting Gemma 3's pre-training quality.
Industry Impact and Future Implications
T5Gemma 2 accelerates the shift toward hybrid encoder-decoder models in open AI, challenging decoder-only dominance from competitors like Meta's Llama series. Its on-device focus aligns with rising demands for privacy-preserving AI, evident in Vertex AI's evolution—from Agent Engine previews in July 2025 to expanded Model Garden support.
For developers, the release lowers barriers: compact sizes enable experimentation on consumer hardware, while multimodal features unlock innovations in AR/VR, healthcare imaging (echoing MedGemma), and enterprise search. Analysts predict widespread adoption in business growth tools, as the model scales from prototypes to production seamlessly.
Broader implications include enhanced AI safety and accessibility. By open-sourcing these weights, Google fosters community fine-tuning, potentially rivaling closed models like GPT variants. However, challenges remain: ensuring equitable multilingual performance and mitigating biases in vision tasks require ongoing scrutiny.

Screenshot from Google Cloud docs showing T5Gemma models in Vertex AI Model Garden, with deployment options for Gemma family.
As AI ecosystems mature, T5Gemma 2 exemplifies efficient scaling. Its timely December 2025 launch, amid Vertex AI's rapid updates (e.g., Gemini 2.5 integrations earlier in the year), reinforces Google's leadership in foundational models. Expect fine-tuned variants and third-party integrations to proliferate, driving the next wave of intelligent applications.



